The hidden impact of Reinforcement Learning’s unseen influence.
 Tendai Bepete, July 2024 – 7 min read
Tendai Bepete, July 2024 – 7 min read 
Image source: Unsplash, © google deepmind, CC BY 2.0.
Have you ever wondered how a robot learns to navigate a room or how a game-playing AI gets so good at winning? The secret sauce behind these smart behaviours is Reinforcement Learning (RL). Reinforcement Learning is a fascinating branch of machine learning where an agent learns to make decisions by interacting with its environment. It’s a powerful tool for training software to achieve optimal outcomes, especially in complex and dynamic environments. In this blog, I’ll be going into a brief but comprehensive guide to what reinforcement learning is, how it works, its various types, key concepts, benefits, real-world applications, and the challenges faced.
What is Reinforcement Learning?
In a nutshell, reinforcement learning trains software to make decisions that maximise rewards over time. It closely resembles how humans learn from their actions: we receive positive reinforcement for good behaviour and negative consequences for bad behaviour. It learns from the feedback of each action and self-discover the best processing path to achieve outcomes (more on that later on).
The algorithm is also capable of delayed gratification. The best overall strategy may require short-term sacrifices. The best approach they discover may include some punishment or backtracking along the way. Reinforcement learning is a powerful method that helps artificial intelligence systems achieve optimal outcomes in unseen environments.
How does Reinforcement Learning work?
The process of reinforcement learning is akin to behavioural psychology. Imagine a child learning that helping with chores earns praise while misbehavior leads to time-outs. RL algorithms operate on a similar principle, experimenting with different actions to understand which yield rewards and which result in penalties. This trial-and-error approach allows the algorithm to refine its strategies over time to maximise positive outcomes.
Types of Reinforcement Learning Algorithms
Reinforcement learning (RL) uses trial and error to train an “agent” to make optimal decisions in an environment. There are many RL algorithms, each with its strengths and weaknesses. Here are some common categories we’ve seen (this is not a complete list as RLs are being developed constantly):
- Q-Learning: An off-policy algorithm that seeks to learn the value of actions.
- Policy Gradient methods: Directly optimize the policy by adjusting parameters.
- Monte Carlo methods: Learn from complete episodes to estimate value functions.
- Temporal difference learning: Combines ideas from Monte Carlo methods and dynamic programming.
- Trust Region policy optimisation: A deep reinforcement learning algorithm for neural networks.
Trust region policy optimisation is one of the deep reinforcement learning algorithms for neural networks where all these algorithms can be grouped into two broad categories, which are model-based and model-free reinforcement learning.
Model-based and Model-free reinforcement learning
Model-based reinforcement learning is used in well-defined, static environments. The agent builds an internal model to predict future states and rewards. Model-free reinforcement learning is ideal for large, complex, and dynamic environments. The agent learns through direct interaction with the environment, without building an internal model.
The key concepts of reinforced learning
In reinforcement learning, an agent interacts with its environment by taking actions. The environment provides rewards (positive, negative, or neutral) as feedback. The agent learns by aiming to maximise its cumulative reward (total reward over time) through trial and error. The state represents the current situation the agent is in, which can be a simplified description or a complex data structure depending on the environment. The ultimate goal of an RL agent is to learn a policy, which is a mapping from states to actions, that maximises its long-term reward.
The key concepts are the following which we will use in the diagram below.
- Agent: The decision-maker or learner.
- Environment: The space in which the agent operates, defined by variables, bounded values, rules, and valid actions.
- Action: A step the RL agent takes to navigate the environment.
- State: The environment at a given point in time.
- Reward: The positive, negative, or neutral feedback for taking a certain action.
- Cumulative Reward: The sum of all rewards over time.
At every step, the agent takes a new action that results in a new environment state. Likewise, the current state is attributed to the sequence of previous actions. Through trial and error in moving through the environment, the agent builds a set of if-then rules or policies. These policies help the agent to decide which action to take next for optimum cumulative reward.
The agent must also choose between failed environment exploration to learn new state action rewards or select non-high reward action from the given state. This is what we call the exploration-exploitation trade-off.
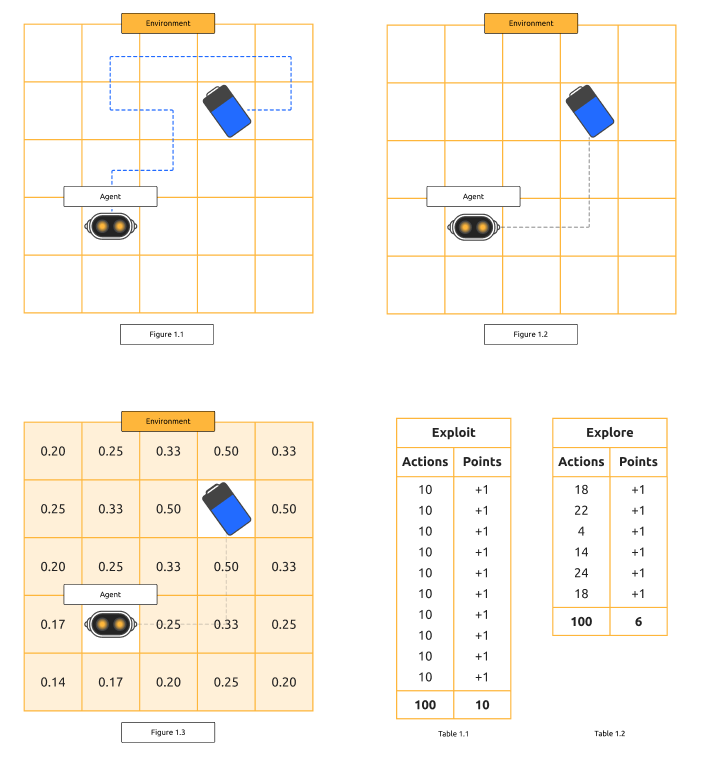
The robot and the war room
Imagine a robot navigating a room to find a charging station (see Fig. 1.1). Initially, it needs to explore to find the station. Once it knows the path, it must decide whether to stick to this path (exploit) or explore further to find a potentially shorter route (see Tables 1.1 and 1.2).
When the robot moves in any direction, its state changes, but it won’t know whether moving in that direction is beneficial until it reaches its goal (see Fig. 1.1). The robot needs to explore the room until it finds the battery. Once it reaches the battery, it’s rewarded (e.g., a score of +1). By looking back at the path taken and assigning values to each step (higher values for steps closer to the goal), the robot gains more information about better actions for future attempts (see Fig 1.2 and 1.3). Starting from the beginning, the robot can now decide on a policy to maximize the reward, following the path it knows will lead to the battery.
While this path may be long and winding, introducing exploration allows the robot to find potentially shorter paths. If the robot explores for a set number of actions (e.g., 100), it may find a shortcut that only takes four actions to reach the goal. This new policy is more efficient, though exploration incurs a cost as the robot may take inefficient paths during this phase (see Tables 1.1 and 1.2).
If the robot continuously follows the same 10-action path, it will consistently get the reward but may miss out on more efficient routes. By exploring, it found a 4-action path. Now, if we compare the two bots over 100 actions:
- The bot using the 4-action path will score more points in the long run (e.g., 25 points) compared to the bot using the 10-action path (e.g., 10 points).
Thus, reinforcement learning requires balancing exploration and exploitation. Should we explore more to find even better paths, or should we exploit known paths to collect more points immediately? This balance is important in many reinforcement learning applications.
Could it be beneficial to us?
In short, yes, Reinforcement learning (RL) offers significant benefits that make it highly valuable in various applications in excelling in complex environments, reduced need for human interaction, and optimisation for long-term goals.
Reinforcement learning performs exceptionally well in complex environments with many rules and dependencies. Even humans with superior knowledge might struggle to determine the best path in such environments. Model-free reinforcement learning algorithms, however, adapt quickly to continuously changing conditions and discover new strategies to optimize results.
In traditional machine learning algorithms, humans must label data pairs to guide the algorithm. With reinforcement learning, there is no need for such human input, as the algorithm learns by itself. Additionally, RL offers a mechanism to integrate human feedback, allowing systems to adapt to human preferences, expertise, and corrections.
Focusing on long-term reward maximization, Reinforcement learning makes it ideal for scenarios where actions have prolonged consequences. It is particularly suited for situations where feedback isn’t immediately available for each step, as it can learn from delayed rewards. For example, in energy consumption or storage decisions, RL can optimize energy efficiency and reduce costs by considering the long-term impact of actions.
Examples of real-world applications of Reinforced learning
We’ve seen the use of reinforcement learning in market personalisation. In applications like recommendation systems, reinforcement learning can customize suggestions to individual users based on their interactions. This leads to more personalised experiences.
Market personalization
An application may display ads to a user based on some demographic information. With each ad interaction, the application learns which ads to display to the user to optimize product sales. We‘ve all come across this when we use applications whereby we get these adverts opening up. If you interact with those adverts, you’re indicating to it what you prefer. The next time you open the app, it will display adverts tailored to your preferences. If you frequently travel between cities, and you use an app to make your booking for those flights, you’re going to notice that each time when you open and use that app, whatever adverts that you might have been using to interact with that app, it will show your preferences.
Optimisation challenges
Traditional optimisation methods solve problems by evaluating and comparing possible solutions based on certain criteria. In contrast, reinforcement learning introduces learning from interactions to find the best or near-optimal solutions over time A cloud spend optimisation system uses reinforcement learning to adjust to fluctuating resource needs and choose optimal instance types, quantities, and configurations. It makes decisions based on current and available cloud infrastructure, spending, and utilisation.
For example, if you’ve used AWS, you might have noticed that the billing dashboard recommends cost-saving options or purchase types for certain instances. If AWS sees that you’ve consistently used a particular type of instance, it may recommend paying in advance for those instances. This reduces costs because you’re indicating a commitment to using those instances in the future.
Financial prediction
Another real-world application used with reinforcement learning is financial prediction. The dynamics of financial markets are complex with statistical properties that change over time. Reinforcement learning algorithms can optimize long-term returns by considering transaction costs and adapting to market shifts. For instance, an algorithm could observe the rules and patterns of the stock market before it tests actions and records associated rewards. It dynamically creates a value function and then develops a strategy to maximise profits. So these are some of just three main cases of reinforcement learning.
Conclusion
Reinforcement learning is a dynamic and powerful tool in the AI toolkit, capable of handling complex and changing environments with minimal human intervention. As we continue to develop and refine Reinforcement Learning algorithms, their applications will only grow, driving advancements in various industries and enhancing our ability to solve complex problems. At StructureIt, we always aim to learn and understand more about the changing technologies in this market to better benefit our clients’ needs. By staying at the forefront of RL advancements, we can ensure we’re delivering the most effective and innovative solutions possible.










