Applying bond similarity within the commercial real estate markets.
 Hugo Valent, Oct 2024 - 4 min read
Hugo Valent, Oct 2024 - 4 min read 
Image source: Image source: Pexels Cottonbro studios
Bond similarity plays a key role in the commercial real estate and credit markets, especially when it comes to building diverse portfolios in sectors like Commercial Mortgage-Backed Securities (CMBS). It refers to techniques used in machine learning and data analysis to measure how similar or related different items or entities are, often used in recommendation systems and clustering algorithms.
This short guide will give you a step-by-step approach to how you can start computing bond similarity using a sample dataset and a machine learning model. Our primary focus will be on the distance metrics used to calculate the similarity between bonds, example, focusing on distance metrics.
Distance metrics explained
Distance metrics are mathematical tools that measure how far apart two data points are. When it comes down to bonds, these metrics help us figure out how similar, or different they are based on their bond characteristics (also called “variables” or “features”).
Think of it like measuring the gap between two numbers ,for example, the distance between 10 and 6 is |10 – 6| = 4 and even when swapped around, the distance between 6 and 10 is also |6 – 10| = 4. This principle can be extended to compare bonds by evaluating the differences in their key characteristics.
Feature engineering
The key characteristics of a bond can also be called variables or features and their selection is particularly important in achieving valid results. Each feature can be fed to the model in its raw or transformed state. If its a standard, well understood value like the price of a bond then it may be safe to use its value raw. However, standard checks for data validity still apply, such as that price is not missing or infinitely large, but the value itself may not need transformation. A variable like interest rate is a percentage that can be transformed into a base percentage value (5.23% to 523bps).
Nearly all variables will need some form of feature engineering or data cleaning to handle missing values, inconsistent/incorrect values, or duplicate values. Once we have a dataset of meaningful features of our bonds we can proceed with computing their similarity.
Computing bond similarity: An example
Let’s compute the similarity between five hypothetical bonds.
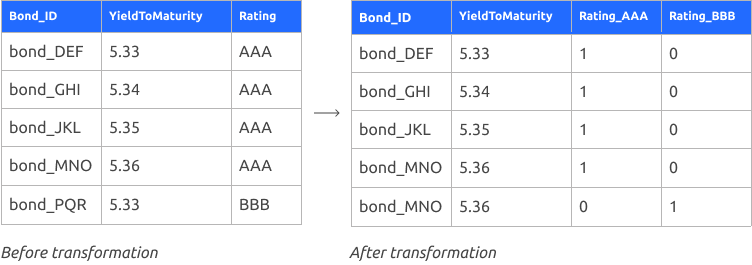
The key steps involve:
1. Selecting relevant features: Choose variables that describe a bond well, like yield to maturity and rating.
2. Transform features: Certain variables, like bond ratings (e.g., AAA, BB), are not directly interpretable by distance metrics as they are categorical rather than numerical. To address this, we transform the rating into numeric values. For instance, encode rating=AA as 1 and 0 otherwise, and then produce another encoding for rating=BB as 1 and 0 otherwise. That way each bond ends up with 1, 0 or 0,1 reflecting whether its AA rated or BB rated. Additionally, we split each rating into its own column so that the encoded values correctly reflect the bond’s rating.
3. Computing the distance: Using the Euclidean distance formula, we compute the distance between each pair of bonds.
The formula is as follows: Distance = sqrt{(x2 – x1)²+(y2 – y1)²+ ••• + (z2 – z1)²}
Let’s calculate the distance between bond_DEF and bond_PQR:
Step 1: Compute the squared difference for each feature.
- yieldToMaturity: (5.33 – 5.33)^2 = 0
- rating_AAA: (1 – 0)^2 = 1
- rating_BB: (0 – 1)^2 = 1
Step 2: Sum the squared differences.
- 0 + 1 + 1 = 2
Step 3: Take the square root of the sum.
- sqrt{2} = approximately 1.41
Understanding the results
In the example above, we calculated the distance between bond_DEF and two other bonds.
The results show that:
- The distance between bond_DEF and bond_PQR is 1.41.
- The distance between bond_DEF and bond_MNO is 0.03.
Since a smaller distance indicates greater similarity, bond_MNO is more similar to bond_DEF than bond_PQR.
Using a vector database
A vector database is going to see every row of our sample dataset (omitting the ID) as an individual vector. Below is a representation of the individual rows without IDs but preserving the order (or some other way of tracing back each vector) of the original sample dataset above.
![]()
Each one of these vectors is going to be processed individually by the DB. Depending on what storage (indexing) method we choose we can constrain the search for similar bonds to pre-computed groups of vectors or choose to search across all of the stored vectors for maximum accuracy. Vector Databases support a number of different models that compute distances, including models that compute distances the way we described above.
Wrapping up
This method shows how to measure bond similarity using distance metrics, especially Euclidean distance. By changing categorical variables into numbers and applying distance calculations, we can see how similar bonds are to each other. This approach helps with tasks like building portfolios and managing risk in capital markets.





